
Technical Update #9: Enhancing Interactions with Chat Prompting
Introducing Conversational AI through Dynamic Prompting

In our ongoing mission to enhance AI interactions, Seraphnet is pleased to announce a significant upgrade to our system: the transition from hardcoded prompts to chat prompting, powered by the DSPy paradigm.
This marks an important milestone in our journey to create more natural, adaptive, and context-aware AI conversations.
Moving Beyond Fixed Prompts
Traditionally, our AI system relied on fixed prompts – static, unchanging queries that limited the potential for dynamic, multi-turn interactions. Users would submit a single query or command, receive a response, and the conversation would end there.
This one-way communication style lacked the adaptability needed to truly understand and meet the evolving needs of our users during a session.
Embracing the Power of Chat Prompting with DSPy
Inspired by current research and industry best practices, we're now implementing a chat prompting approach that transforms AI interactions into fluid, conversation-like exchanges.
Central to this transformation is the DSPy framework, a powerful tool for algorithmically optimizing large language model (LLM) prompts and weights, particularly when LLMs are used one or more times within a pipeline.

Before DSPy, building complex AI systems with LLMs required a laborious process: breaking down the problem into steps, meticulously crafting prompts for each step, tweaking the steps to work harmoniously, generating synthetic examples for tuning, and using these examples to fine-tune smaller LLMs for cost efficiency. This approach was cumbersome and inflexible, demanding significant rework whenever the pipeline, LLM, or data changed.
Leveraging the DSPy paradigm allows our AI system to engage in multi-turn dialogues, allowing users to ask follow-up questions, provide additional context, and refine their queries based on previous responses.
DSPy streamlines the optimization of prompts and weights, enabling our AI to adapt dynamically to the conversation flow and user needs. This two-way communication unlocks a new level of understanding between users and our AI, as the system can ask clarifying questions to better grasp the user's intent and tailor its responses accordingly.
The result is more accurate, relevant, and personalized outputs that truly meet the user's requirements.
Reducing Hallucinations through Advanced Prompt Engineering
A key motivation behind our transition to chat prompting is the goal of minimizing "hallucinations" – plausible but factually incorrect outputs generated by AI models.
Hallucinations occur when an AI system confidently generates responses that seem coherent and believable but are not grounded in reality or supported by factual evidence. This can happen when the model tries to fill in gaps in its knowledge or when it overextends its understanding of a topic.
Our team has closely studied various methods for structuring prompts to guide language models towards producing more truthful, rational, and commonsensical outputs.
Some of the key techniques we're incorporating include:
Retrieval Augmented Generation (RAG): RAG systems combine the capabilities of language models with external information sources. By retrieving relevant context from knowledge bases before text generation, we can ground our AI's responses in factual evidence, reducing the likelihood of unsubstantiated speculation.
ReAct Prompting: ReAct or Recursive Assistant prompts are designed to query the model recursively about its own thought process and confidence levels at each step. By encouraging deep introspection and calibration of uncertainty, we can surface gaps in the model's knowledge and improve the truthfulness of its responses.
Chain-of-Verification (CoVe) Prompting: CoVe prompts explicitly require the model to provide step-by-step verification for its responses by citing external authoritative sources. This approach reduces unmoored speculation by scaffolding a chain of reasoning grounded in verifiable facts at each step.
Chain-of-Note (CoN) Prompting: CoN prompts aim to improve model understanding by explicitly logging context, thoughts, and gaps encountered along the path to formulating a response. By tracing the model's evolving reasoning and surfacing blind spots, we can incorporate additional context to improve the accuracy of the final answer.
Chain-of-Knowledge (CoK) Prompting: CoK prompts require the model to source its responses from chains of expert knowledge to reduce logical leaps or false inferences. By compelling the model to situate its responses in established knowledge from multiple domain experts, we can reduce the risk of unsupported opinions or faulty conclusions.
In addition to these techniques, we're also exploring other advanced prompting methods such as veracity classification, factual history and future analysis, and alternative perspective prompting. By explicitly encoding the evidentiary, logical, and contextual backing required for reliable claims, these prompts help to mitigate the risk of hallucination.
However, we also recognize that prompt engineering alone is not a complete solution to AI safety. It is crucial to instill an innate sense of honesty in our models about the frontiers of their competency. By transparently acknowledging the limitations of their knowledge and capabilities, our AI can manage user expectations and foster responsible cooperation between humans and machines.
Implementing Best Practices in Prompt Management
To ensure the success of our chat prompting implementation, we're also adopting industry-leading practices in prompt management. By establishing a robust prompt management framework, we're enabling more effective collaboration among our team members and streamlining the development and optimization of prompts.
Our prompt management strategy includes:
Maintaining a Change Log: We keep track of prompt changes by storing each version of a prompt in our Git repository. This allows us to easily revert to previous versions for debugging or understanding past issues.
Decoupling Prompts from Application Code: For better security and access control, we keep our prompts in a separate repository from our application code. This allows us to manage access to prompts without exposing our entire codebase.
Modularizing Prompts: We design reusable components and utilize interpolated variables to keep our prompts flexible and easy to update. This modular approach saves time and helps maintain consistency across different parts of our application.
Monitoring Usage and Costs: We keep a close eye on how much we're using and spending on LLMs, as costs can quickly add up, especially when using third-party providers. By monitoring usage and costs, we ensure that our project stays on budget.
Regularly Evaluating Prompt Effectiveness: To ensure our prompts are delivering the desired results, we set up a comprehensive tracking system that captures prompts, inputs, outputs, and detailed metadata such as the LLM version and configuration settings. This allows us to analyze performance across different scenarios and models, and continuously refine our prompts.
Implementing these best practices in prompt management, we're not only enhancing the effectiveness of our chat prompting implementation but also fostering a collaborative environment where our team can work together to create powerful, user-centric AI interactions.
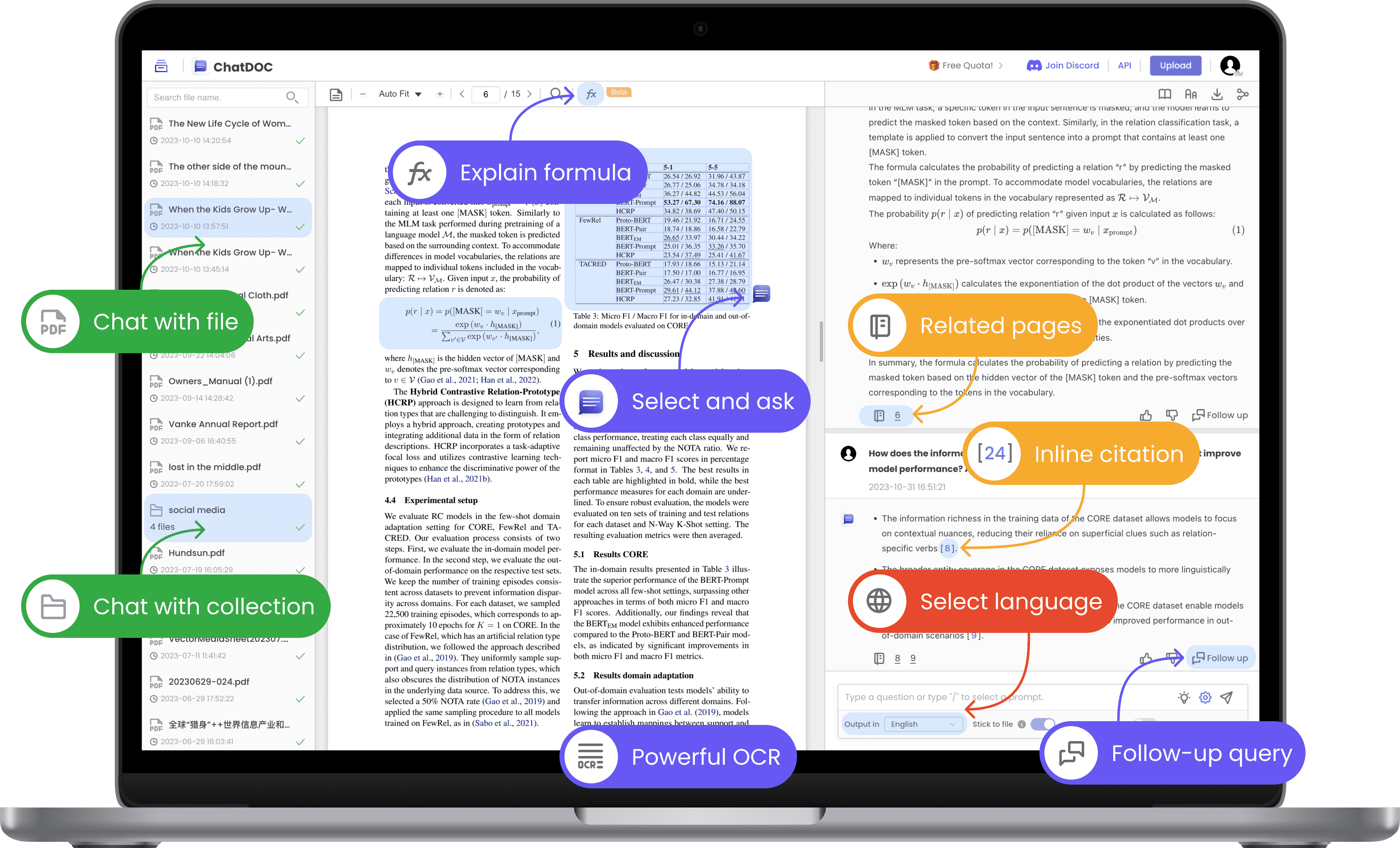
Modeling Our Solution After ChatDoc's Paradigm
After thorough analysis of various AI-powered document interaction architectures, our R&D team has chosen to model our chat prompting solution after the paradigm exemplified by ChatDoc. This decision was driven by ChatDoc's focus on usability, accurate and contextually relevant responses, and fast response times.
This architecture leverages advanced NLP techniques to provide accurate, context-aware responses and concise summaries of PDF content. This greatly enhances accessibility and usability, enabling users to quickly find the information they need without reading the entire document.
The following paradigm maintains the coherence of the conversation by understanding the context of user queries and providing relevant responses. It also emphasizes fast response times through efficient indexing and retrieval techniques, ensuring a smooth, interactive user experience.
The Future of AI Interactions
As we deploy this update and transition to chat prompting, we're setting the stage for new possibilities within our infrastructure. With more natural, adaptive, and context-aware conversations, our AI system will become an even more powerful tool for our users, providing insights, assistance, and support tailored to their unique needs.
Stay tuned for further updates as we continue to innovate and set new standards in AI interaction. Together, we're not just advancing technology – we're shaping the future of how humans and machines collaborate and converse.
PS: Want to read more? Make sure to subscribe to our Substack if you haven't already!